Als Datenquelle kommt der "10k German News Articles Dataset (10kGNAD)" zum Einsatz. Entnommen wurde er von Kaggle: https://www.kaggle.com/tblock/10kgnad
Die vorgefertigte Aufteilung in Trainings- und Testdaten wurde rückgängig gemacht und selbst neu angefertigt.
Für die Auswertung kam Tensorboard zum Einsatz. Mit diesem Tool kann der Verlauf des Lernprozesses sehr schön visualisiert werden. Dafür muss Tensorboard installiert sein (pip install Tensorboard)
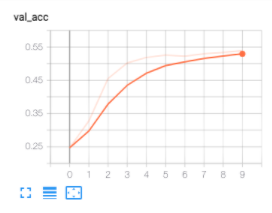
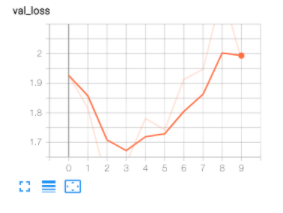
Ergebnisse
Loss/Accuracy nach 10 Epochen:
Epoch 10/10
8218/8218 [==============================] - 11s 1ms/step - loss: 0.2515 - acc: 0.9293 - val_loss: 2.2044 - val_acc: 0.5189
 Klick: Komplette Arbeit auf meinem GitHub-Account
Klick: Komplette Arbeit auf meinem GitHub-Account